
 澳门六合彩
澳门六合彩
传统的债券失约模子主要分为线性模子和非线性模子。线性模子如AltmanZ-score通过财务比率得出笼统风险评分,方便易用,但财务蓄意有限,可能无法全面反馈债务东说念主情状。非线性模子如Merton模子基于期权订价表面,巧合更好地捕捉钞票波动,但对参数依赖较大,且冷漠进步性事件。与之比拟,机器学习在债券失约风险评估中具有上风,巧合通过自动化数据分析挖掘复杂的非线性关连,处理大界限数据和缺失值,并及时相宜商场变化。机器学习的浩大自相宜性和精准性使其成为传统失约模子的繁难补充,提高了瞻望准确性并应酬商场复杂性。上市公司债券信用风险识别不仅有助于债券商场的投资,相同巧合动作一个细密的股票筛选因子。
在数据集的时刻区间永诀上,为了确保西宾集和测试集比例接近7:3,凭证失约数据的分散笃定2022年8月动作分界区分失约数据的西宾集以及测试集,并遴荐2022Q1的财报数据动作西宾集,并使用2024Q2的财报数据动作测试集。同期,为了提高样本的针对性,在普通样本中仅保留公司债和可转债两类,从而缩短数据异质性,优化模子的泛化性能。特征中式方面,笼统琢磨企业运营与债券特质,诠释中式了财务、债券本色以及股票往复三大类蓄意。针对数据抗击衡问题,诠释中秉承的欠采样战略不仅有用均衡了数据分散。通过这种处理设施,模子在数据勾通对少数类(如失约样本)的识别智商显贵增强。同期,在样本数目有限的情况下,尽量保留了繁难的异质性信息,确保模子巧合捕捉到要道的风险特征。
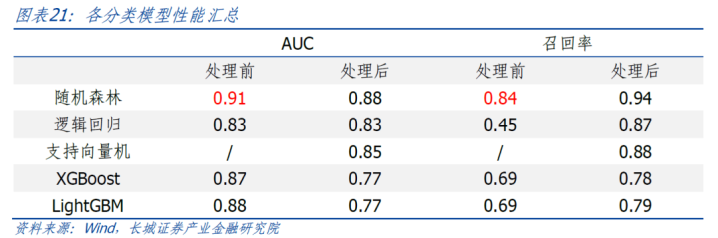
咱们使用了逻辑归来、就地丛林、援手向量机、XGBoost以及LightGBM五个分类模子。由于援手向量机必须使用调解量纲后的数据,在磨练五个模子的情况后咱们发现调解量纲的操作将会显贵提高每个模子的调回率,而这有可能是由于引入将来数据导致的。为了幸免将来函数的问题,咱们将不再琢磨援手向量纯真作信用风险识别模子。在剩余的四个模子中,就地丛林不论是在AUC如故调回率上齐具备显然的上风,AUC达到0.90,调回率达到0.84。
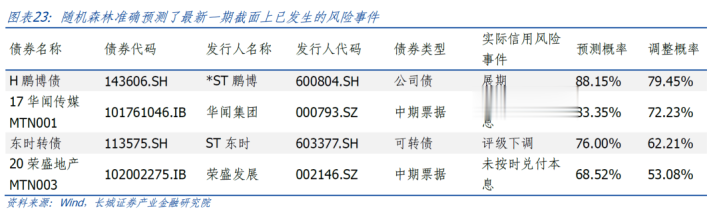
使用就地丛林动作瞻望最新一期债券信用风险的模子,中式2024年11月1日至2024年12月20日的信用风险样本以及2024Q3截面的普通样本组成考证集,关于依然产生的信用风险事件,就地丛林均给出了相瞄准确的分类(瞻望概率均大于50%),况且休养概率均大于50%。关于截面上存续的可转债,共有11支可转债的失约休养概率越过50%。
风险指示:数据中式未使用全部数据,可能导致样本偏差;特征中式存在一定主不雅性;数据抗击衡采样设施可能导致信息丢失;历史数据无法饱胀瞻望将来终结;模子存在失效可能性。
1
使用机器学习识别信用风险
传统的债券失约模子大约可分为线性模子和非线性模子两大类。线性模子中,最具代表性的如AltmanZ-score模子,该模子通过计较多个财务比率并加权得出一个笼统风险评分,方便易用,但其局限性也较为显然,主要在于中式的财务蓄意较少,可能无法全面反馈债务东说念主的财务情状。非线性模子方面,最具代表性的为Merton模子,它基于期权订价表面,将企业失约界说为企业钞票价值小于债务账面价值,使用Black-Scholes公式对企业的股票和欠债进行估值,从而推算失约概率。此模子巧合较好地捕捉钞票价钱波动,但在本质欺诈中对参数的依赖较大,且未能琢磨进步性事件的影响。
机器学习动作对债券商场传统失约模子的繁难补充,主要体目下其浩大的数据处聪慧商和自相宜特质。传统模子经常依赖于固定的财务蓄意和简便的假定,可能难以捕捉债券失约风险中潜在的复杂非线性关连。而机器学习模子巧合自动从大量历史数据中挖掘潜在的要领和形式,尤其在面临非线性特征时发达出色。除此以外,机器学习设施巧合有用处理大界限数据和缺失值,幸免了传统模子在数据作假足时的局限性。由于其浩大的自相宜性,机器学习模子不错跟着商场环境的变化及时更新,提供愈加精准和个性化的风险评估。这些上风使得机器学习在债券商场中的欺诈不仅提高了瞻望的准确性,还巧合更好地应酬商场的动态变化和复杂性,从而成为传统失约模子的有用补充。
为了便于读者清爽诠释的内容,咱们在开篇率先梳理整个这个词模子从搭建、西宾到瞻望的经过。整个这个词经过大约分为4步,不雅察的确全国中数据的分散情况并构造相宜于分类学习模子的数据集,中式不同维度的因子,使用不同的分类模子(如逻辑归来、援手向量机、就地丛林等)西宾并测试模子,并给出最新一期的瞻望情况。
上市公司债券信用风险识别的兴趣兴趣不单是停留在于关于债券风险的回避,其相同不错用于对上市公司股票的筛选。若是将上市公司对应的债券信用风险动作一个筛选股票池的因子的话,其相同具有细密的终结。统计2016年5月1日至2024年8月31日之间发生信用风险的债券对应的上市公司在财报限度日之间的发达(假定某支债券发生信用风险的日历为2016年5月13日,则对应的区间为2016年5月1日至2016年8月30日),以中证800动作基准,逾额收益为负的占比为73.03%,逾额收益的中位数为-14.18%。这就意味着不错通过剔除瞻望可能发生信用风险的上市公司来进行股票战略的增强。

2
数据处理与特征遴荐
数据截面中式
信用风险样本与普通样本的抗击衡性
在本篇诠释中界说的信用风险事件包括两个大类:一个是发生实质性失约事件的债券,包括本息失约、提前到期未兑付、缓期资金未兑付等;另一个则是信用评级下调事件。
在数据整理阶段,咱们率先对信用风险样本进行梳理,并凭证信用风险样本的分散情况从普通样本中“匹配”对应的子集。这一处理的中枢原因在于,信用风险样本与普通样本之间存在严重的抗击衡性。若是平直将全部普通样本纳入模子,数据的抗击衡将显贵影响模子的性能,使其倾向于瞻望多数类(即普通样本),从而疲塌模子对少数类(即信用风险样本)的识别智商。
以2022年5月1日至8月31日的区间为例(2021年年报&2022年一季报截面),2022年4月30日存量上市公司信用债的数目为41365个,而在上述区间中发生信用风险的债券数目系数为243个,占全部信用债的比例约为0.59%。较着,若是将全部截面的普通样本全部纳入数据集,会形成严重的数据抗击衡,从而影响模子的性能。因此,咱们将率先处理信用风险样本,并将信用风险样本按照比例进行永诀,进而笃定使用的普通样本的截面。
失约以及评级下调数据处理
关于失约数据,率先在wind结尾债券——信用债接洽——债券失约——债券失约及缓期大全中拉取特定时刻内整个失约及缓期的债券信息。本文接洽从2015年年报及2016年一季报发布限度日历(2016年4月30日)运转,拉取2016年5月1日起于今整个失约及缓期的债券,债券分类中剔除金融债。
关于评级下调数据,率先在wind结尾债券——信用债接洽——评级预警——债项评级调低债券拉取特定时刻内整个评级下跌债券评级调低对应的时刻。本文接洽从2015年年报及2016年一季报发布限度日历(2016年4月30日)运转,拉取2016年5月1日起于今整个债券评级下调债券分类中剔除国债、所在政府债、央行单据、同行存单以及金融债。
上述设施拉取的excel中并不包含债务主体的有关信息,为了便于后续因子数据的拉取,咱们在excel中索取对应信息。由于wind无法平直通过债券代码索取对应债务主体代码,咱们将其拆解为两步:1.索取债务主体中语简称;2.中语简称调治为wind代码。
针对吞并债务主体在吞并季度内有多个不同债券信用风险的情况,咱们保留其中上市日历最早的债券的信用风险纪录;针对吞并个债券在吞并个季度内的多条信用风险纪录,保留失约日历最早的纪录。
信用风险数据集永诀
为了测试模子在完好截面数据(对全部)上的智商,咱们单独保留最新截面(2024Q3财报限度日)动作考证集。关于剩余的信用风险数据,咱们尝试找寻一个财报限度日截面,使得西宾集与测试集的永诀比例最接近7:3。凭证计较,2016年5月至2024年10月的信用风险样本按7:3永诀的时刻节点为2022年8月29日,因此咱们秉承2022年一季报截面永诀西宾集以及测试集(对应信用风险样本区间为2022年5月至2022年8月)。
普通样本
凭证上述信用风险数据集的永诀,咱们笃定2022年一季报截面以及2024年中报截面分别动作西宾集以及测试集的普通样本时刻。由于普通样本数目较多,因此在普通样本中咱们将仅保留公司债与可转债两个大类。
抗击衡样本数据处理
在信用风险接洽中,数据抗击衡性是一个需要重心处分的问题。经常,失约样本相较于非失约样本数目少许,这种样本比例的分歧称会导致瞻望模子偏向多数类(即非失约样本),从而缩短对少数类(即失约样本)的瞻望准确性和识别智商。在处理这种抗击衡问题时,常用的技能包括过采样(Oversampling)和欠采样(Undersampling)。
过采样通过加多少数类样本数目来均衡数据集,这不错通过重叠少数类样本或生成合成样本(如使用SMOTE等设施)来已矣。然而,过采样可能会导致模子过拟合,尽头是在少数类样本数目本就帮忙时,这种问题尤为显然。
欠采样则是通过从多数类样本中就地移除部分数据或基于某种战略遴荐子集,使多数类和少数类的样本数目畸形或接近。固然欠采样巧合有用减少样本抗击衡的影响,但同期也可能导致繁难信息的丢失,尤其是在多数类样本中包含了大量有价值的异质性信息时。
为了在信用风险瞻望中尽可能保留与风险事件有关的繁难信息,本文秉承了一种基于欠采样的战略进行数据抗击衡处理。在此经过中,保留整个失约样本(或信用评级被下调的债券样本),并从普通样本(非失约样本)中就地抽取数目畸形的子集,组成与失约样本均衡的西宾集。通过这种设施,既均衡了数据集的类别分散,幸免模子过于偏向多数类,又尽可能缩短因欠采样而丢失要道信息的风险。在这个系列诠释中咱们将调解使用RandomUnderSampler将普通样本的数目删减至与信用风险样本一致。
特征中式
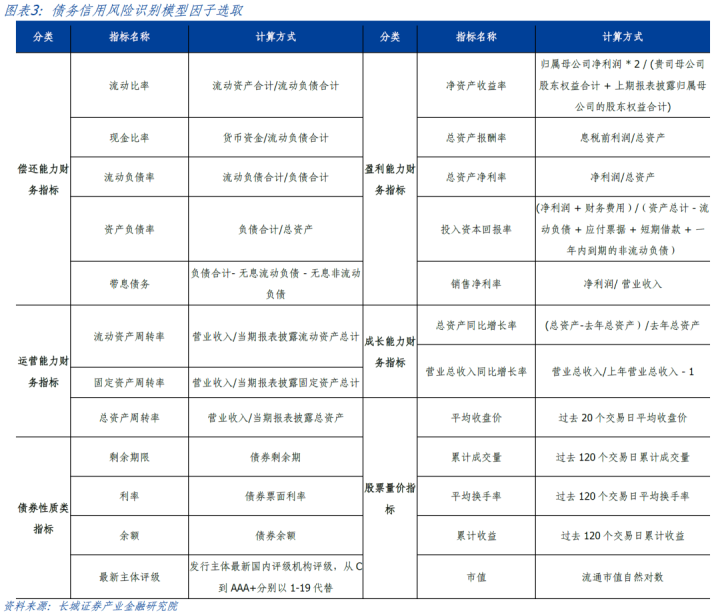
在寻找特征时,率先是巧合直不雅体现企业老本结构及运营情况的各项财务蓄意。模仿国内多家书用评级公司的评级逻辑,分别中式反馈企业偿债智商、盈利智商、成长智商的多项财务比率,进行上市公司财务情状的评价。其次,琢磨到信用债自身的特质,中式和债券性质有关的蓄意,包括债券余额、票面利率、剩余期限、最新主体评级。终末,凭证退市新规的条件,纳入往复性退市有关的股票量价信息,包括累计成交量、平均收盘价、累计收益等。
特征中式前,西宾集/测试集/考证集的失约数据分别有358/149/5条;西宾集/测试集/考证集的非失约数据分别有660/711/684条。
剔撤除缺失值占数据集数目越过百分之三的因子之后,西宾集/测试集/考证集的失约数据分别有328/128/4条;西宾集/测试集/考证集的非失约数据分别有632/686/662条。
3
分类模子西宾与测试
模子评估参数先容
污染矩阵(ConfusionMatrix)是分类模子评估的一个繁难器用,用于展示模子在各个类别上的瞻望终结与本质标签之间的各异。它通过四个基本值来刻画模子的发达:真确例(TP),即瞻望为正类且本质为正类的样本;假正例(FP),即瞻望为正类但本质为负类的样本;真反例(TN),即瞻望为负类且本质为负类的样本;假反例(FN),即瞻望为负类但本质为正类的样本。污染矩阵不仅不错匡助咱们计较诸如精准度、调回率和F1分数等评价蓄意,还能直不雅地展示模子在不同类别上的分类终结,尽头是在类别抗击衡的情况下,提供比准确率更为全面的评估。
调回率,也叫真确率(TruePositiveRate),是分类模子性能的一个繁难蓄意,估量模子正确瞻望正类样本的智商。其计较公式为:调回率=真确例/(真确例+假反例)。调回率越高,阐述模子能更多地识别出正类样本,适用于需要关爱“漏检”问题的场景(如信用风险识别)。不外,调回率高也可能导致假阳性加多,因此经常需要与精准度(Precision)等其他蓄意沿途笼统评估。
ROC弧线是一种通过刻画不同有蓄意阈值下分类器的性能来评估其发达的器用。在该弧线中,横轴暗意假阳性率(FPR),纵轴暗意真确率(TPR),也即是调回率。ROC弧线经常用于二分类问题,匡助不雅察分类器在各个阈值下的聪敏度与特异性。ROC弧线越集合左上角,阐述分类器的性能越好。
AUC指的是ROC弧线下的面积,它是一个笼统性蓄意,用来量化分类模子的全体发达。AUC值的范围是0到1,越接近1暗意模子的性能越好,越接近0则暗意模子的性能较差。AUC的直不雅含义是“就地挑选一个正类和一个负类样本,模子将正类样本排在负类样本之前的概率”。当AUC为0.5时,暗意模子的性能与就地算计相配。
逻辑归来
以交叉考证笃定LASSO的正则化参数,拟合Logistic归来模子,在测试勾通以AUC和调回率对模子进行评估。基于欠采样的就地性,进行100次模拟,统计分析西宾终结。AUC基本保执在0.80-0.85之间,平均值0.83。中式其中一条ROC弧线展示如下,对应AUC值为0.80。调回率基本保执在0.42-0.52之间,平均调回率0.45。
就地丛林
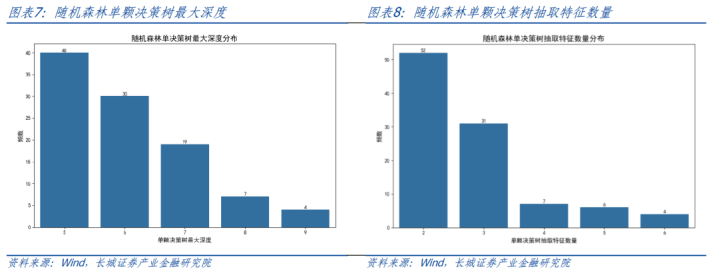
以交叉考证笃定就地丛林的参数,包括单颗有蓄意树的最大深度以及抽取特征的最大数目,最终在测试勾通以AUC和调回率对模子进行评估。
就地丛林算法自己即秉承了bagging算法,表面上欠采样的就地抽取对终结影响不大,因此仅进行100次模拟西宾,统计分析西宾终结。交叉考证所得最优参数分散如下,平均最大深度6,平均抽取特征数目2.79,约为总特征数44的6%。
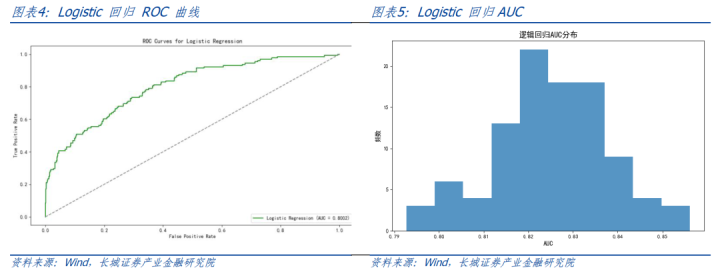
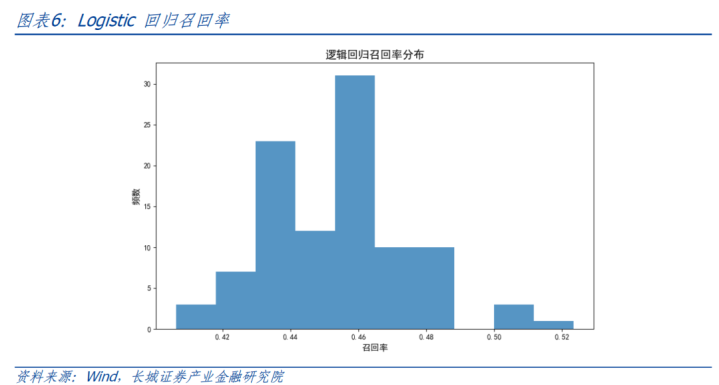
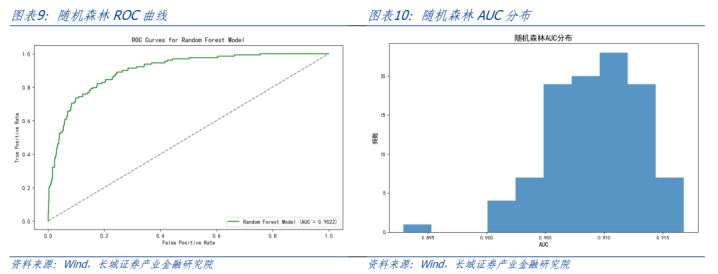
AUC基本保执在0.9-0.92之间,平均值0.91。中式其中一条ROC弧线展示如下,对应AUC值为0.90。调回率保执在0.76以上,平均调回率0.84。
日前,宜宾市商业银行股份有限公司(以下简称宜宾银行)通过港交所聆讯。这是宜宾银行第三次向港交所递表,2023年6月,宜宾银行向港交所提交了上市申请,首次递表失败后,宜宾银行在2024年3月第二次递表港交所,但也已于10月初失效。
字节跳动2025年资本开支预算飙升至近1600亿人民币,其中约900亿人民币用于AI算力采购,其余700亿人民币分配给IDC基建以及网络设备。多重利好消息下,推动了算力方向持续活跃。
援手向量机
指定核函数为sigmoid,在测试勾通以AUC和调回率对模子进行评估。基于欠采样的就地性,进行100次模拟,统计分析西宾终结。AUC基本保执在0.84-0.88之间,平均值0.86。中式其中一条ROC弧线展示如下,对应AUC值为0.85。调回率基本保执在0.80-0.94之间,平均调回率0.88。

XGBoost
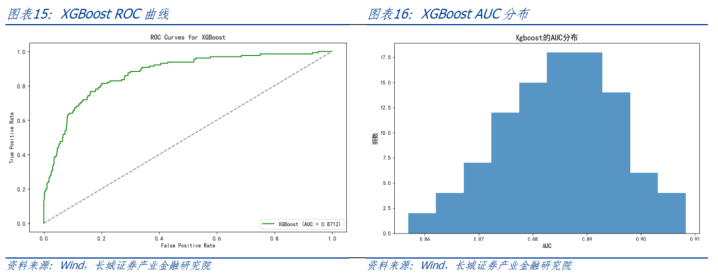
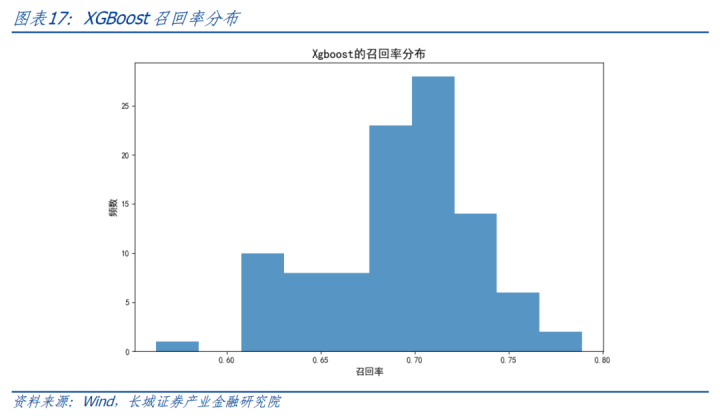
以交叉考证笃定Xgboost的参数,包括最大深度、学习率和,最终在测试勾通以AUC和调回率对模子进行评估。基于欠采样的就地性,进行100次模拟,统计分析西宾终结。AUC基本保执在0.86-0.90之间,平均值0.88。中式其中一条ROC弧线展示如下,对应AUC值为0.87。调回率基本保执在0.60-0.75之间,平均调回率0.69。
LightGBM
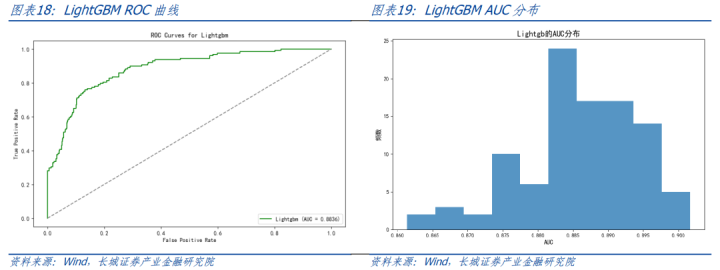
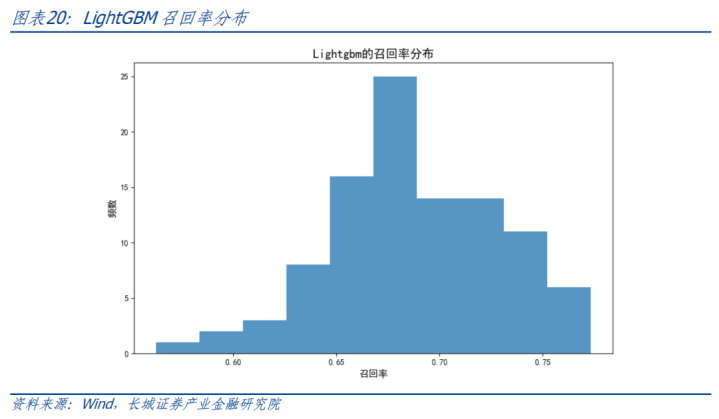
以交叉考证笃定LightGBM的参数,包括最大深度、学习率和,最终在测试勾通以AUC和调回率对模子进行评估。基于欠采样的就地性,进行100次模拟,统计分析西宾终结。AUC基本保执在0.86-0.90之间,平均值0.89。中式其中一条ROC弧线展示如下,对应AUC值为0.88。调回率基本保执在0.60-0.75之间,平均调回率0.69。
各种模子性能比较
鉴于援手向量机所使用西宾集数据是经过调解量纲处理的(这是由于援手向量机必须要均衡整个特征的量纲,否则将导致模子依赖量纲最大的特征),而其他模子的西宾集并莫得作念交流处理,接下来调解使用处理后的西宾集,评估模子发达。
使用调解量纲处理后的西宾集的各个模子的AUC齐有所缩短、调回率大幅提高,平均调回率提漂后过10个百分点。琢磨到失约数据并作假足是吞并截面的,调解量纲的处理就会存在一定的将来函数问题。凭证4个模子的情况来看,调回率的提高主要源于调解量纲的操作。为了幸免将来函数的问题,咱们将不再琢磨援手向量纯真作信用风险识别模子。
在剩余的四个模子中,就地丛林不论是在AUC如故调回率上齐具备显然的上风。因此,遴荐就地丛林动作瞻望最新一期债券信用风险的模子。
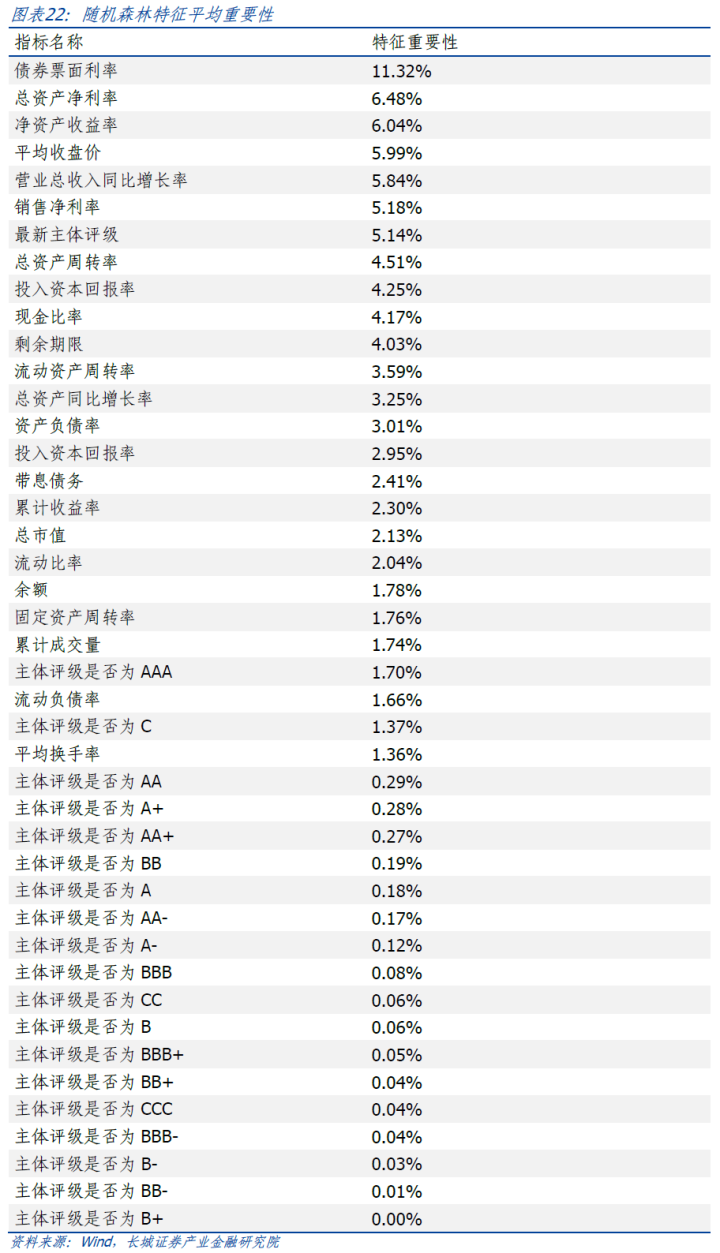
特征繁难性
特征繁难性(FeatureImportance)是指在机器学习模子中,各个特征对瞻望终结的孝敬进程。通过评估特征的繁难性,咱们不错了解哪些特征在模子有蓄意经过中起到了要道作用,哪些特征可能是冗余的或不繁难的。特征繁难性经常通过模子的西宾经过计较获取,关于树模子(如有蓄意树、就地丛林、XGBoost等),它经常基于特征对信息增益、分裂节点的影响等进行评估。高繁难性的特征意味着它们对模子的瞻望终结影响较大,低繁难性的特征则可能不提供有价值的信息。特征繁难性不错匡助咱们优化模子、进行特征遴荐,以致提高模子的可阐述注解性。
计较就地丛林模子中特征的平均繁难性,名次前10的特征中有7个为对应上市公司财务蓄意,2个债券本色有关蓄意以及1个上市公司股票量价有关蓄意,前10名蓄意的系数占据58.92%的繁难性。
4
最新截面债券信用风险瞻望
中式2024年11月1日至2024年12月20日的信用风险样本以及2024年第三季报截面的普通样本组成考证集,咱们率先对比在最新一期截面发生的信用风险事件以及模子给出的瞻望概率情况。不错看到,关于依然产生的信用风险事件,就地丛林均给出了相瞄准确的分类(瞻望概率均大于50%),况且休养概率均大于50%。
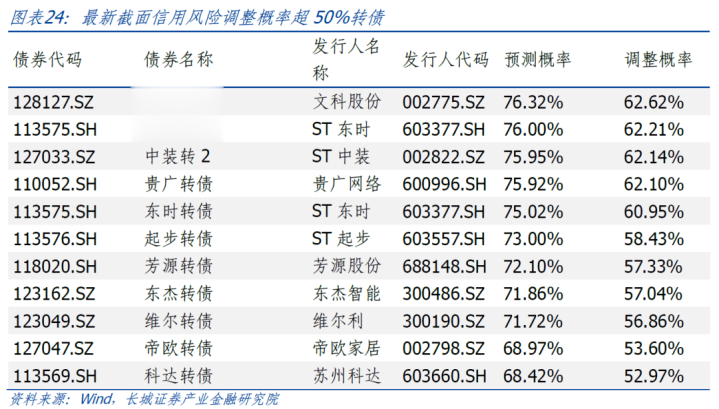
咱们给出最新一期截面上瞻望信用风险休养概率越过50%的转债方向。包含依然产生信用风险的转债,共有11支。
风险指示
数据中式未使用全部数据,可能导致样本偏差;特征中式存在一定主不雅性;数据抗击衡采样设施可能导致信息丢失;历史数据无法饱胀瞻望将来终结;模子存在失效可能性。
证券接洽诠释:
《上市公司债券信用风险识别模子》
对外发布时刻:
2025年1月8日
诠释发布机构:
长城证券股份有限公司(已获中国证监会许可的证券投资讨论业务经验)
本诠释分析师:
尽头声明:
长城证券股份有限公司(以下简称长城证券)具备中国证监会批准的证券投资讨论业务经验。
接洽诠释是基于本公司以为可靠的已公开信息,但本公司不保证信息的准确性或完好性。接洽诠释所载的贵寓、器用、认识及推测只提供给客户作参考之用,并非动作或被视为出售或购买证券或其他投资方向的邀请或向他东说念主作出邀请。在职何情况下澳门六合彩,接洽诠释中的信息或所表述的认识并不组成对任何东说念主的投资提倡。在职何情况下,本公司分歧任何东说念主因使用接洽诠释中的任何内容所引致的任何耗损负任何包袱。